5_PPO
代码 12_PPO.ipynb
#机器学习/强化学习/同策略 #机器学习/强化学习/连续动作 #机器学习/强化学习/离散动作
1. 网络结构
和优势演员评论员机制一样,评论员采用Q网络,演员采用梯度网络。
不同点在于引入重要性采样和裁剪,重要性采样使得内部可以使用异策略的方法,让 state 不具有序列相关性,而且通过裁剪的方法确保了每次更新幅度不会过大,通过多次学习可以比较精细地调整。
2. 重要性采样
PPO 限制了更新的大小,称为 裁剪,因此对于同一批数据可以多次训练,相当于局部的异策略学习,这样数据利用率会比较高。
但是在内部的每一次训练中,实际上只有第一次是在线学习,因为第一次更新采用的经验就是当前策略的,但是已经更新一次之后,策略就变了,而数据还是之前的,这时就类似离线学习了,为了确保新策略和原来的策略不会有太大偏差,就加了重要性采样。在PPO算法内部的更新,严格来说还是离线学习,尽管是进行一整轮游戏之后采取更新。但是由于这种离线学习是建立在在线学习的大框架里面的,所以一般说PPO是在线学习,即同策略。
#机器学习/强化学习/重要性采样 #机器学习/强化学习/异策略
对于重要性采样,推导如下
我们再纳入优势函数A,优势函数的推导参考优势函数推导,此时可以写出梯度的公式,推导参考#目标函数推导
那么根据
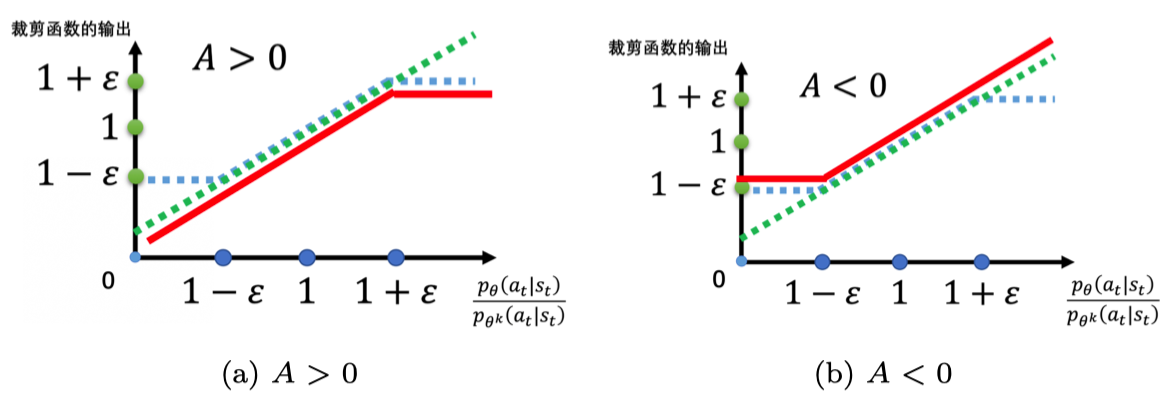
3. PPO截断
再加上截断技巧,演员网络目标函数如下(未取均值),应使其最大化,因此代码中还加了负号
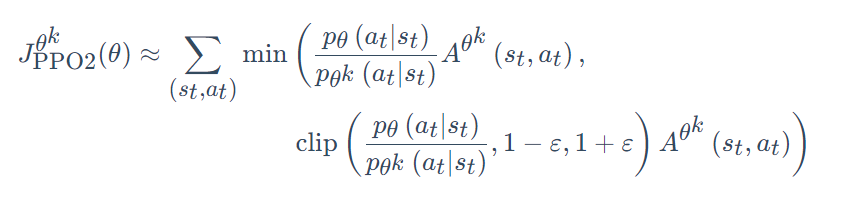
原本是重要性乘以优势函数再乘以演员动作概率的对数,但是与环境交互的演员变成另一个演员了,这个演员在代码中就是原本那个每次训练刚开始时候的初始状态的演员,相当于一个原始副本。
根据A的正负不同,有如下图示,蓝色虚线表示裁剪范围,红色表示最终最小值输出