1_DQN
代码 07_DQN.ipynb 08_DQN的改进.ipynb
本笔记用于复习DQN及其改进技术以及过拟合研究,本文的环境都是OpenAI的开源库gymnasium的Pendulum-v1,其给的最大奖励是0,也就是直立状态,其他状态都给负奖励,因此可以以0为基准讨论过拟合问题。

1. 深度 Q 网络
1.1. 什么是Q网络
#机器学习/强化学习/价值网络 #机器学习/强化学习/异策略
Q 网络接收 state 的输入,如果是离散动作,则输出每个动作对应的 Q 值,可以选择 Q 值最大的那个动作;如果是连续动作,由于动作的取值是无限的,就需要确定一个动作取值和状态一起输入网络,Q 网络就只输出价值,确定动作通常依靠策略网络。
相关资料:Q网络和梯度网络的区别。
1.2. 核心理解
在普通 DQN 中,我们会建立两个Q网络,一个是原 Q 网络,参数为
#机器学习/强化学习/过拟合
Q网络的思想就是用神经网络来预测当前状态下各动作的价值,利用时序差分方法更新策略,即网络参数。在后续演员评论员框架的改进中,评论员网络通常是Q网络,采用时序差分方法更新,演员采用梯度策略更新。Q网络和V网络在实际应用中通常使用同一个网络,有时候可能叫Qnet,有时候叫ValueNet,实际上通常是同一个东西。
深度 Q 网络的关键在于时序差分方法更新网络参数
#机器学习/强化学习/时序差分
其中目标Q值也可以写成如下式子,因为
完整损失函数(目标函数)可以写为
其中 是批量均值, 是最后两个值的均值,该公式求使损失最小的参数 ,在程序中不用写这么复杂:
# pytorch 2.0.1
# states和actions等都是一个批量的数据,tensor类
import torch.nn.functional as F
import torch
q_net = Qnet().to('cuda')
target_q_net = Qnet().to('cuda')
optimizer = torch.optim.Adam(q_net.parameters(), lr=learning_rate) # Adam优化器,这里选择只更新q_net参数
...
Q_value = q_net(states).gather(1, actions) # 依据当前动作选出该动作的Q值
Q_target = r + gamma * target_q_net(next_states).max(1)[0].view(-1, 1) * (1 - dones | truncated) # 直接选出最大的Q值
loss = torch.mean(F.mes_loss(Q_value, Q_target)) # 求批量的均方差之后再求均值,即1/2N
optimizer.zero_grad() # 设置0梯度避免积累
loss.backward() # 反向传播计算梯度
optimizer.step() # 执行梯度下降
1.3. 改进方案
1.3.1. Double DQN
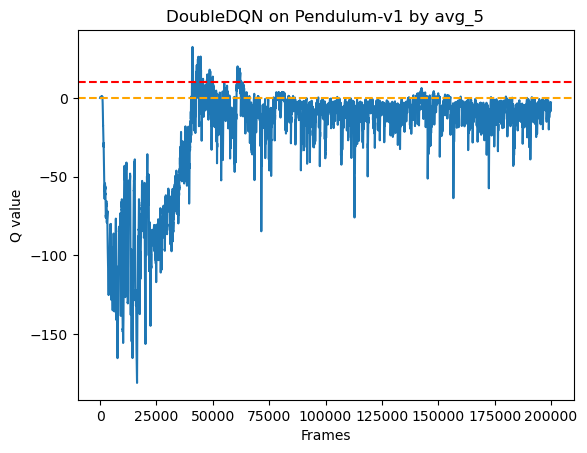
在普通 DQN 中,目标网络总是选择最大的 Q 值,虽然比从原网络直接估计 Q 值要好,但也有可能过拟合,比如对一个奖励最大就是 0 的环境来说,Q 网络要拟合它的奖励,尽管越往后总体会越趋近于 0,但是它有可能输出会大于 0,目标 Q 网络同理,因此如果总是选目标 Q 网络估计的最大 Q 值,那就有可能把原 Q 网络往输出大于 0 的方向引导,造成过拟合,或者说过高的 Q 值估计。
前面提到目标 Q 网络的更新是比较慢的,假设原网络已经过拟合了,我们的目标 Q 值还是用目标 Q 网络估计,但不选择最大的那个 Q 值,而选择原网络最大 Q 值对应的那个动作,按照这个动作去选择目标 Q 网络给出的 Q 值,因为目标 Q 网络更新的比较慢,所以可能没有原网络那么过拟合,所以选到的 Q 会比较低,这样原 Q 网络的参数就会调整得不那么过拟合,从而一定程度抑制了过拟合。
这样的修改可以写成如下公式,区别就是选择动作的网络变了,变成原网络,从参数上看得出来
代码方面有如下改动
# ======> # 下个状态的最大Q值, Double DQN的区别
if self.dqn_type == 'DoubleDQN' or 'DuelingDQN': # 先在q网络确定动作, 再对应到目标网络的价值上
max_action = self.q_net(next_states).max(1)[1].view(-1, 1)
max_next_q_values = self.target_q_net(next_states).gather(1, max_action)
else: # DQN的情况, 直接用目标网络估计价值
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)
这样的改动是有效果的,如下图
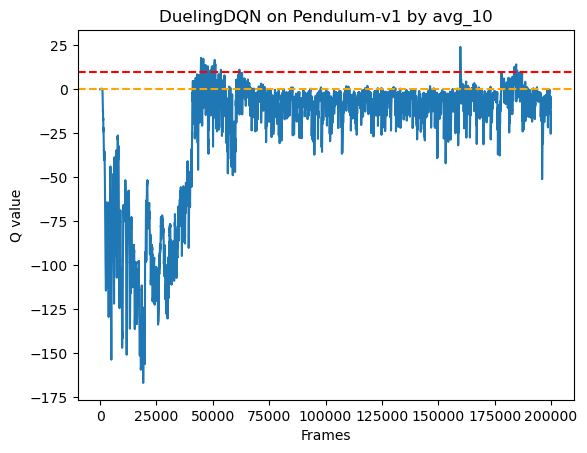
本文的环境是 Pendulum-v1,其给的最大奖励是 0,也就是直立状态,其他状态都给负奖励,普通 DQN 在一些轮次中,估计的 Q 值比较大,有的接近 10,也就是过拟合,右边的 Double DQN 中,在 epsilon降低之后的训练中出现了严重过拟合,但是在后期稳定之后就很少过拟合了,但还有一个缺点,就是有的轮次的 Q 值突然下降,说明对于该轮次选择的动作学习的不好,因为网络每次只是针对选择的一个动作造成的误差进行梯度下降,这样就忽略了其他动作的学习,如果有状态动作没有被采样到,就没有被很好的学习到。
1.3.2. Dueling DQN
主要区别是网络设计上,普通 DQN 的网络一般如下
class Qnet(torch.nn.Module):
''' 只有一层隐藏层的Q网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x)) # 输出一个Q值
return self.fc2(x)
Dueling DQN 采用对偶输出的设计,共用一个隐藏层,但是输出层输出两个值,并且加和作为最终输出,这里引入优势函数的概念,其设计如下
class VAnet(torch.nn.Module):
''' 只有一层隐藏层的A网络和V网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(VAnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 共享网络部分
self.fc_A = torch.nn.Linear(hidden_dim, action_dim)
self.fc_V = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
A = self.fc_A(F.relu(self.fc1(x))) # 状态动作优势
V = self.fc_V(F.relu(self.fc1(x))) # 状态价值
Q = V + A - A.mean(-1).view(-1, 1) # Q值由V值和A值计算得到, 关于为什么减去A.mean,后面有解释
return Q
优势函数 A 实际上是 A = Q - V,即估计的 Q 值减去当前状态的价值 V 等于动作优势 A,这样更好理解,但是我们需要网络给出 Q 值,因此写成 Q = V + A。
A 和 Q 的公式中有两个参数 s,a,所以叫状态动作优势/价值,但是不代表输入网络两个参数,我们只需要输入 s;V 只有一个参数 s,但输出只有一个,表示当前状态的价值。Q 和 V 都接收 s,因此前几层可以共用。
V 值,代表当前状态的价值,如果是一个批量,那么有两个维度,大小是(批量数, 1);另一个是 A,表示当前动作的相对优势(人为定义的),它类似传统的 Q 值,即给出了该状态下每个动作的 Q 值,如果输入的是一个批量,那么大小是(批量, 动作空间);其中 A 类似之前输出 Q 值,因为每个动作都对应一个 Q 值,而 V 是一维的,代表每个状态的一个状态价值。所谓状态价值,可以理解为有的状态很差,无论采用什么动作都很难获得比较好的回报,那么这时候状态价值就很低,反之同理。
- 关于为什么 A 要减去
- 在网络中需要限制 A 的更新,
, 减去 ,会使得 A 整体更接近 0,并且均值为 0,这是为了减少 A 在梯度下降中的调整大小,从而使得梯度下降主要影响 V,V 的输出比较简单,也好调整一些,而改变了 V,也就同时改变了所有动作的 A 值(矩阵运算的广播机制),等于改变了所有动作的 Q 值(同时增加或者减少),因此在某个状态下的学习会对所有动作的估计产生影响,而不是只改变 Q 值最大的那个动作的估计。
- 在网络中需要限制 A 的更新,
在前面的普通 DQN 和 Double DQN 中,没有 A 和 V 的概念,网络直接输出 Q,在反向传播中,只考虑了 Q 值最大的那个动作,就只是考虑了该动作造成的误差。
这样的改动也是有效果的, Deuling DQN 后期 Q 值出现大幅下降的情况减少了,并且下降的幅度也变小了,如下图
1.4. 关于过拟合的研究
Double DQN 的目的是抑制过拟合,但是无法完全避免,实际上动作空间越大越容易过拟合。
设动作空间为 m,也就是有 m 个动作可供选择,假设状态
的分布函数如下:
又因为各动作是独立的,一共有 m 个动作,因此对于使得误差最大的动作 有分布函数:
对该分布函数求期望: