Residuals
残差:不止统计
1. 小麦农场
假如我们在一个农场中工作,负责种植小麦,作为具有扎实科学素养的高材生,我们就会想了解种植小麦的产量与其他因素之间的关系。为了研究这个问题,我们收集了多年的数据,包括小麦产量,以及可能影响产量的因素,如降雨量、温度和施肥量等。我们很轻松地将这些数据输入统计软件中进行分析。
在分析过程中,我们使用了一个称为“回归模型”的统计工具,该模型可以帮助我们理解小麦产量与其他因素之间的关系。通过回归模型,我们可以得到一个预测方程,该方程可以根据输入的因素值来估计小麦产量。
然而,真实世界往往是复杂和多变的。尽管我们使用了回归模型来预测小麦产量,但实际观测值与预测值之间会存在差异。这个差异就是残差。
残差代表了实际观测值与回归模型预测值之间的差异。它可以用来衡量模型的准确性和预测的可靠性。如果残差接近于零,就意味着模型能够很好地解释数据,预测值与实际观测值相吻合。而如果残差较大,就意味着模型无法完全解释数据中的变异性,或者存在其他未考虑的因素。
比如回归方程考虑了全部因素,其表达式是
通过观察和分析残差,我们可以发现一些隐藏的规律。例如,在降雨量较高的年份,小麦产量偏高,而在温度较高的年份,小麦产量偏低。这些发现可以帮助我们做出更准确的决策,合理安排灌溉和调整施肥量,最大程度提高小麦的产量。我们还可以估计是否存在未考虑的其他因素。
残差是数理统计和计量经济学的基础知识之一,我们已经很熟悉了。在系统科学概论课上,丁老师还简单讨论了残差在信号提取中的作用。但笔者并不熟悉信号处理,因此这里笔者结合自己的认识,打算讨论现代机器学习技术中最重要的技术之一——残差网络。
2. 残差网络
今天,当我们提到人工智能中炙手可热的深度学习技术,通常会想到几十上百层的深度神经网络,或者参数量以亿计的 GPT 模型,深度模型的确具有惊人的学习能力。但是如果把目光倒回20年前,会发现人们通常只会尝试构建几层甚至十几层的神经网络,难道神经网络不是越深越好吗?的确,通过增加神经元个数和神经网络层数,会提高神经网络的高维特征提取能力。
但,这一切都建立在何恺明提出的残差网络的基础上,目前残差网络论文的引用数已经超过10万次。
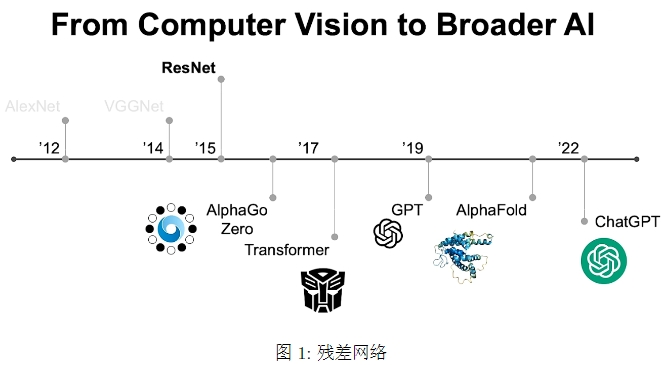
1998年,Yann LeCun 首次提出 LeNet,这是首个卷积神经网络的应用之一,具有两个卷积层、两个池化层和三个全连接层。2012年,AlexNet 成为 SOTA,具有五个卷积层,三个全连接层。2014提出 VGGNet,具有13层卷积和3层全连接层,成为新秀。
后来的模型大家都有所耳闻,比如打败人类顶级棋手柯洁的基于强化学习的人工智能AlphaGo和AlphaZero,以及当今最引人关注的GPT模型。而这一切被称为深度模型的先进算法,无一不以2015年何恺明的ResNet为基础,这就是残差网络。
在传统的神经网络中,每个层的输出是通过将前一层的输出传递给激活函数得到的。然而,当网络很深时,梯度在反向传播过程中可能会逐渐减小,导致较早层的参数更新变得困难,这称为梯度消失问题。
通过残差连接,网络可以直接跳过一些层,将前一层的输出与后续层的输出相加。这样可以确保信息在网络中的传递不会受到限制,即使网络很深,梯度也可以更容易地传播。残差连接允许网络学习残差函数,即前一层输出与后续层输出之间的差异,而不是直接学习映射函数。
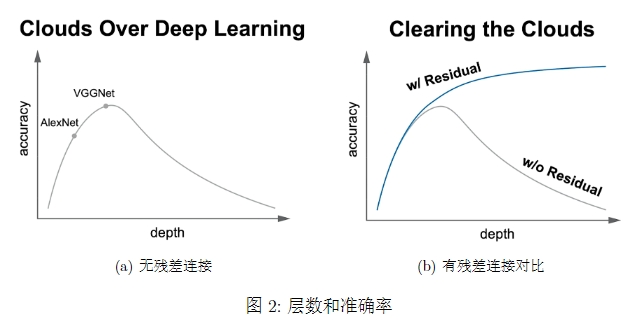
在残差连接技术出现之前,神经网络的深度与准确性的关系通常如图2中灰色曲线。随着层数增加,准确性下降,其原因通常是梯度消失。那么,到底什么是残差网络?残差网络是由一系列残单元块组成的。
在统计学中,残差和误差是非常容易混淆的两个概念。误差是衡量观测值和真实值之间的差距,残差是指预测值和观测值之间的差距。对于残差网络的命名原因,作者给出的解释是,网络的一层通常可以看做
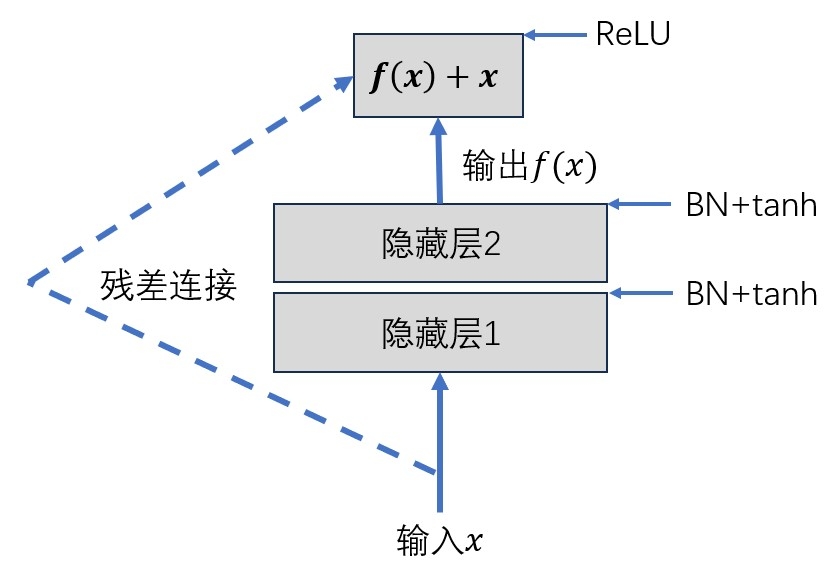
残差单元分为直接映射部分和残差部分,
BN 表示批量归一化,ReLU 和 tanh 表示激活函数,在图残差单元中,输入 x 通过两个隐藏层之后输出
前面提到过梯度消失问题,如果我们用 sigmoid 激活,层数很大时,梯度累乘可能导致梯度消失影响训练效率,在卷积神经网络中,通常用 tanh 激活,也不能避免梯度消失问题,因为训练参数时,我们用到梯度下降,这是一个累乘的过程。
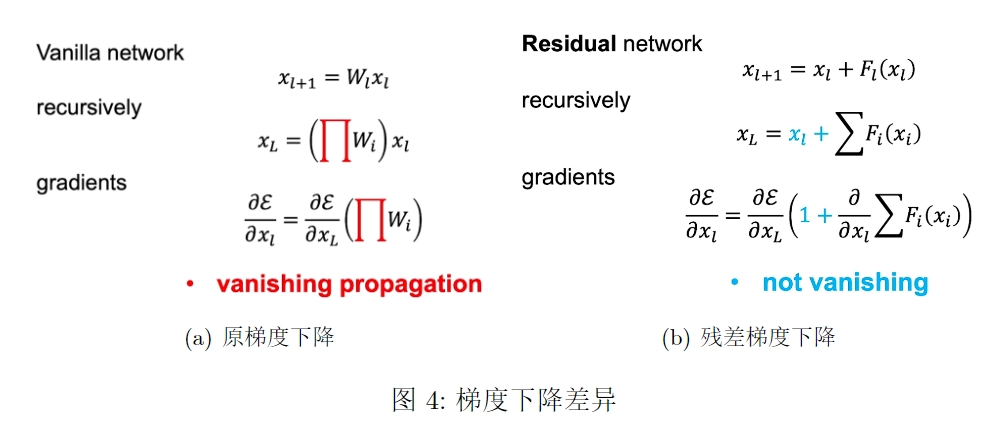
如果很多权重值都是小于1的,累乘起来就会导致偏导数值趋近于0,由于计算机能够处理的小数位是有限的,一旦一个浮点数太小,计算机就只能认为是0,导致梯度消失,网络输出 nan 最终报错,但是一旦把输出改成
就算
这样的改进看起来是很简单的,在代码中构建也的确很简单,只需要在输出层加上一个原本的输入值即可,但是要论证残差连接的合理性仍然有大量工作可以做,比如,残差连接是直接把 x 加到输出层,我们能否在中间加入线性变换。
在原本的残差连接中,
我们采用反证法,假设
对于更深的 L 层
损失函数
上面公式反映了两个属性:
- 当
时,很有可能发生梯度爆炸; - 当
时,梯度变成 0,会阻碍残差网络信息的反向传递,从而影响残差网络的训练。
所以
由于本文不在于解释残差连接的合理性,因此不再讨论。
3. 总结
残差连接在神经网络中具有重要的意义,它缓解了梯度消失问题,支持网络深度增加,提高了网络的收敛速度和训练效率,促进了特征重用和学习,同时也提供了网络修复和模型的可解释性。这些特性使得残差连接成为构建高性能神经网络的关键技术之一。
自残差网络提出以后,人工智能技术发展的速度就大大加快了,2018年用于机器翻译的注意力机制框架Transformer问世,2020年GPT3模型问世,不过寥寥数年,何恺明博士在前不久的报告中再次回顾了这一历程,很难不让人感慨。