04_模型改进技术
有很多方法可以在基本模型的基础上进行调整改进,比如
批量归一化
归一化也就是标准化,英文简称 BN(Batch Normalization),与统计学中的概念一致,但是不要问我为什么
在第三个公式标准化 x 时,分母加了一个
在代码构建中,批量归一化非常简单,在 现有框架实现神经网络的代码基础上,只需要加一个BatchNormalization()
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.BatchNormalization(),
# 每一层中间都加一个批量归一化
keras.layers.Dense(300, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dense(100, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dense(10, activation='softmax')
])
批量归一化在计算机视觉中经常使用,这种技术通常可以把基本模型的精度再提高几个点。
在最先进的架构 Transformer 构架中,作者把批量归一化改成了层归一化,即对每一个样本自身进行归一化,而不是对若干个样本的特征归一化,读者可自行了解,这里不详细说明。
Dropout
在传统机器学习中,正则化通常使用
Dropout 就是在每次训练中随机关闭一些神经元,比如关闭 30%,假如公司规定每天都随机有一些人休息不上班,那么就会空缺一些岗位,剩下的员工就必须尝试兼职那些空缺的岗位,并且加强合作效率,这是对 dropout 产生更好效果的一个比喻,是的只是一个比喻,关于神经网络或者神经元为什么会这样或者那样运作,至今也没有定论,这也就是神经网络的难以解释的特性。通过添加该方法,你的神经网络会更鲁棒,有更好的泛化能力。
在代码中也很容易实现,只需要用 Dropout() 方法,传入一个丢弃率的参数:
# 使用0.2的dropout率在每个Dense层之前应用dropout正则化,它将丢弃一些输入,将剩下的输入传递到下一层
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(300, activation='elu'),
keras.layers.Dense(100, activation='elu'),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(10, activation='softmax')
])
残差连接
这是卷积神经网络中常用的技术,也是划时代的技术,由何恺明、孙剑等人提出,也可以用在普通神经网络中,其结构非常简单,但构建起来会稍微复杂一点。
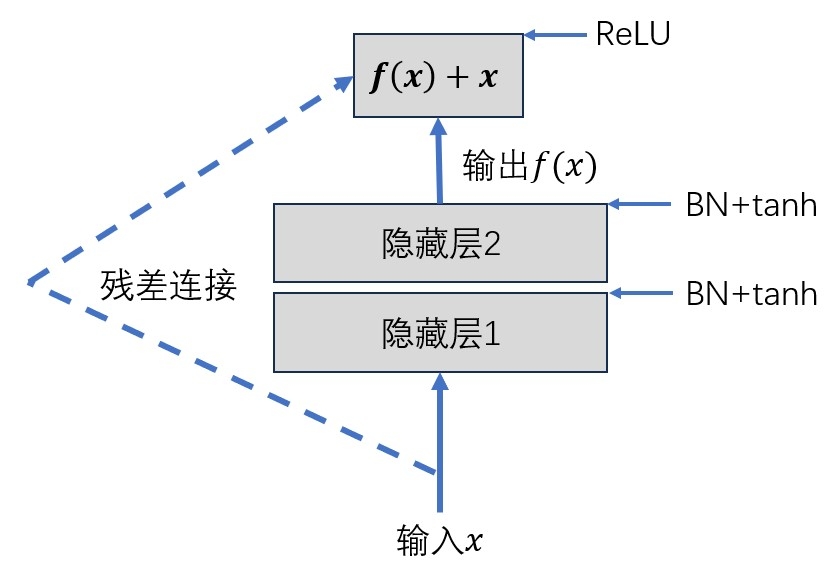
BN 表示批量归一化,ReLU 和 tanh 表示激活函数,在图4.1残差连接单元中,输入 x 通过两个隐藏层之后输出
之前提到过梯度消失问题,如果我们用 sigmoid 激活,层数很大时,梯度累乘可能导致梯度消失影响训练效率,在卷积神经网络中,通常用 tanh 激活函数,也不能避免梯度消失问题,但是一旦把输出改成
就算f(x)的梯度很小,这个偏导也是接近 1 的,从而避免了梯度消失问题。在机器学习中,即便是一个简单的创新,只要对模型有提升,也是划时代的贡献。
代码构建
代码涉及到继承的方法,如果看不懂可以先跳过,代码修改自深度计算机视觉,第 33 个代码块。
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1,
activation="relu", **kwargs):
super().__init__(**kwargs) # 继承父类参数
# 激活函数默认ReLU
self.activation = keras.activations.get(activation)
# 构建两个隐藏层,合并作为主要层,中间有两个BN层
self.main_layers = [
keras.layers.Dense(10, self.activation,
input_shape=[3]),
keras.layers.BatchNormalization(),
keras.layers.Dense(20, self.activation)
keras.layers.BatchNormalization()
]
def call(self, inputs):
Z = inputs # 输入的x赋值给Z
# 让Z经过主要各层,最后Z等于前面图片中的f(x)
for layer in self.main_layers:
Z = layer(Z)
# skip_Z等于我们最开始给的x
skip_Z = inputs
return self.activation(Z + skip_Z) # 实现残差连接