03_机器学习效果评估
一般情况
在现成的机器学习框架中,一般都比较友好地给出了模型返回的一些数据,并且可以方便地作图。此外也可以采用 F 1 分数,PR 图像或者 AUC 图像来衡量模型质量,但是它们通常用于传统机器学习中,在深度学习领域比较少见,因此不在这里介绍。
在前面的机器学习任务代码中,如果我们在后面运行命令:
pd.DataFrame(history.history).plot() plt.grid(True)
plt.gca().set_ylim(0, 1) plt.show()
大概会得到类似下面的图像,
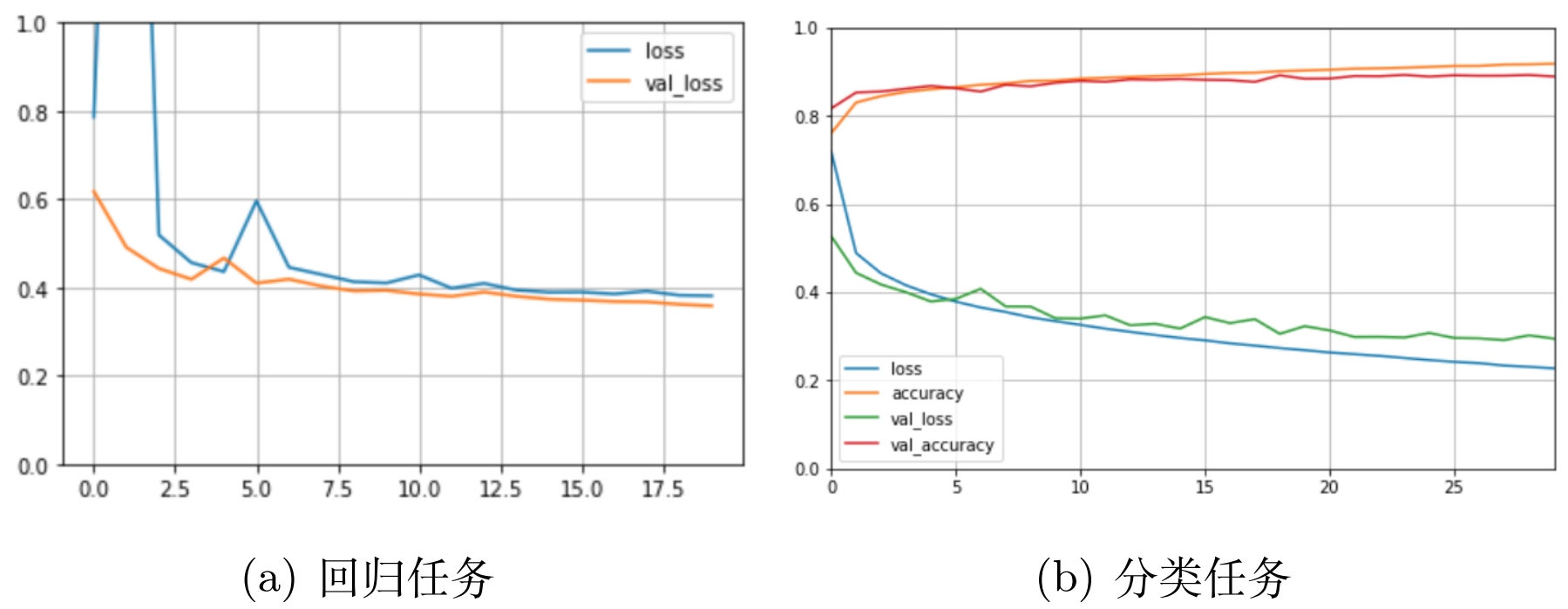
损失曲线剧烈震荡
有时候会出现剧烈震荡,很有可能是因为学习率太大,例如要从 5 调整到 4,但是学习率比较大,比如梯度是-10,学习率是 0.5,那么
确定基准
如何判断
过拟合和欠拟合

如果验证损失明显大于训练损失,说明模型过拟合了,上面的图在 02_神经网络出现过,我们只需要两条大致的直线来拟合数据,而不需要穿过所有的点,如果过拟合了,建议减少神经元个数和层数,因为神经元越多,拟合线越多,层数越大,拟合维度越高,也可以用特殊方法调整权重的初始化值,这些方法可以在 Pytorch 或者 Tensorflow 的文档中找到,在04_模型改进技术中有简单提及。
如果
调整图像
训练集的结果与验证集不是完全同步的,训练误差是使用每个轮次的运行平均值计算的,验证误差是在训练集训练完毕之后,在验证集上测试得到的,虽然测试和验证都是在同一个迭代中完成,但是可以说验证集的
图像是否美观也很重要,模型的效果好也要通过图像表现出来,这就要求你具备良好的调用matplotlib包的能力,此外还有seaborn包,它在前者基础上构建,可以比较轻松地画出更美观的图像。
除了python的包,有时候你甚至可以用Photoshop或者其他绘画软件来作图或者改图,但是不要用它们绘制虚假数据图像。