01_单层感知机
单个神经元的结构
感知机也就是神经元,是 MLP (多层感知机: Multi-Layer Perceptron)的基本单元,这里先学习单个感知机是如何传递信号的。我们在神经网络图像中一般用一个圆来表示一个感知机,一个感知机自带两个公式,一个是
注意:此时
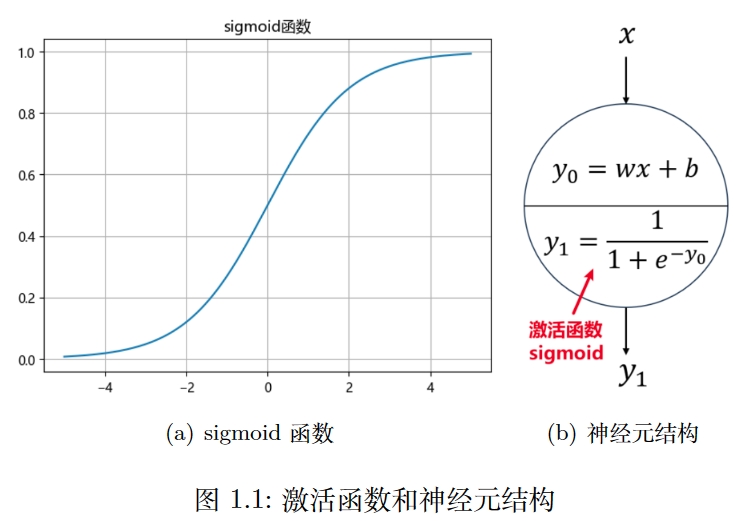
公式 1 是神经元中包含的两个公式,可以合并起来,把
如果此时我要求你对公式 2 计算
如果考虑公式 3,就仅仅需要把
总结一下,神经元接收一个输入(也可以是多个),经过两步运算:1. 线性运算,2. 激活函数,得到一个输出,并且传给下一层所有的神经元,每个神经元都做同样的运算。
激活函数
sigmoid是一个 S 形函数,并且在 x 取无穷大或者无穷小时,其导数接近0,因此也叫饱和激活函数,类似的还有,激活函数有很多种,神经网络拟合函数是靠多个线条组合成的,一个线条来源于一个感知机,这个线条可以是直线,也可以是曲线,它的形状取决于激活函数,激活函数是时,单个线条就是一个曲线,当然,如果把曲线分割成无数段,它也可以是直线的形状。
正如上一节刚开始说的,人们早期使用只是因为它类似真实生物的信号传递特征,但它并不是最优的,它的求导看起来确实非常简单,但能不能更简单呢,最简单的求导是一元一次方程,的导数就是它的系数,并且,激活函数换成直线好像也并不冲突,被无限分割的直线还是直线,被无限分割的曲线呢?每一个部分也是"直线"。
于是现代最常用的激活函数呼之欲出:
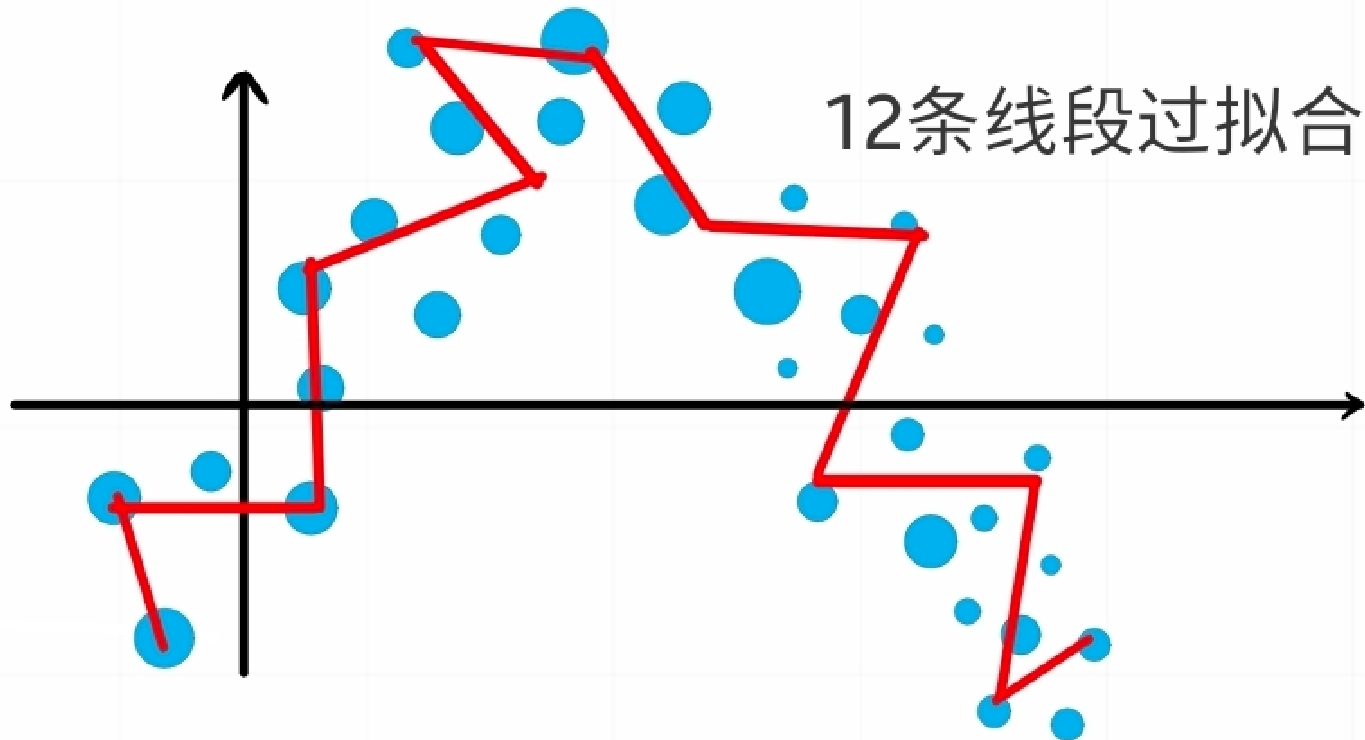
当的结果小于0的时候,经过 Relu 激活输出为0,也就是说它此时"死亡",但不代表与它连接的下一个神经元也"死亡",因为一个神经元实际上要接受上一层所有神经元的信号并且加起来,参考上图。每个神经元初始的和是不一样的,几乎不可能前面那层全都是 0。这有助于防止过拟合,试想,本来5个线段就可以拟合好的函数,现在放置了20个神经元,就有20条线段,那么至多有15个神经元是不必要的,它们凭空增加了计算复杂度,或者造成过拟合,但是残差连接可以改善此问题,在 04_模型改进技术 中具体讨论。ReLU 可以关闭接近一半的神经元:考虑到和刚开始是被认为初始化的,它们被赋予某种分布的某个随机值,通常是标准正态分布的,因此经过公式 1 第一个公式输出的也是正态分布的,小于0的那些神经元就被关闭。
在输出层,如果是回归任务,则没有激活函数,如果是二分类任务,采用激活函数,如果是多分类任务,采用函数。