用户画像算法
用户画像算法和文献解读
1. 计算用户画像标签重要性方法
用户画像是怎么生成出来的? - 朱翔宇的回答 - 知乎
https://www.zhihu.com/question/31429786/answer/1762480989
该方法可以作为特征工程,对于已经打好标签的数据,增加其标签特性作为用户特征,或者仅仅用于刻画标签的特征。
2. 文献解读
2.1. 论文信息
Pujahari A, Sisodia D S. Item feature refinement using matrix factorization and boosted learning based user profile generation for content-based recommender systems [J]. Expert Systems with Applications, 2022, 206: 117849.
直译:基于内容的推荐系统中,使用矩阵分解和增强学习来进行项目特征细化和用户画像生成
期刊:Expert Systems with Applications,一区top,CCF C
关键概念:
- User profile 用户画像;
- CBF(Content-Based Filter)基于内容的过滤器;
- CBRS(Content-Based Recommender System)基于内容的推荐系统,CBRS属于CBF;
- matrix factorization 矩阵分解;
- PCA 主成分分析;
- 物品:指待推荐的项目
2.2. 论文解读(AI辅助)
2.2.1. 研究背景与动机
- 内容推荐系统(CBRS)依赖于物品特征来构建用户偏好模型,但在现实世界的数据集中,物品特征通常不一致且稀疏,这使得构建高效的用户模型变得困难。
- 用户偏好模型的创建者未能从用户评分和偏好的误分类中学习,导致推荐质量下降。
研究动机中,第一点强调物品特征稀疏性和数据缺失问题,即有些特征可能是某个物品特有的,这是为了引出用矩阵分解做特征精炼的点子,第二点是说传统的非学习方法没有持续学习能力,是为了引出机器学习算法,认为机器学习通过用户新的反馈可以继续学习。
2.2.2. 研究方法
针对前面的研究动机,作者提出了两步方法来改进 CBRS 的性能。
-
第一步是使用矩阵分解来细化物品特征中的稀疏性和不一致性。
-
第二步是通过迭代提升多个弱学习器来生成个体偏好模型,以惩罚评分的误分类。
对于第一点,作者采用了一种非常类似于 PCA 的矩阵分解的方法对原始特征矩阵做数据精炼,其方法很大程度采用了 Wang 等人的工作[1];对于第二点,作者简单地采用 AdaBoost 方法作为机器学习模型。
2.2.3. 模型框架
左图是传统框架,右图是本文框架。这里只讨论本文框架。
对于训练部分(右图,左边部分),Items 可以看作是用来训练和验证的关于物品特征原始数据集,原始 Items 数据通过处理、向量化等方法转化为可学习的表征形式,再通过矩阵分解进一步精炼表征,它将和用户特征一起输入集成模型进行训练。
对于新物品的推荐参考(右图,右下部分)。
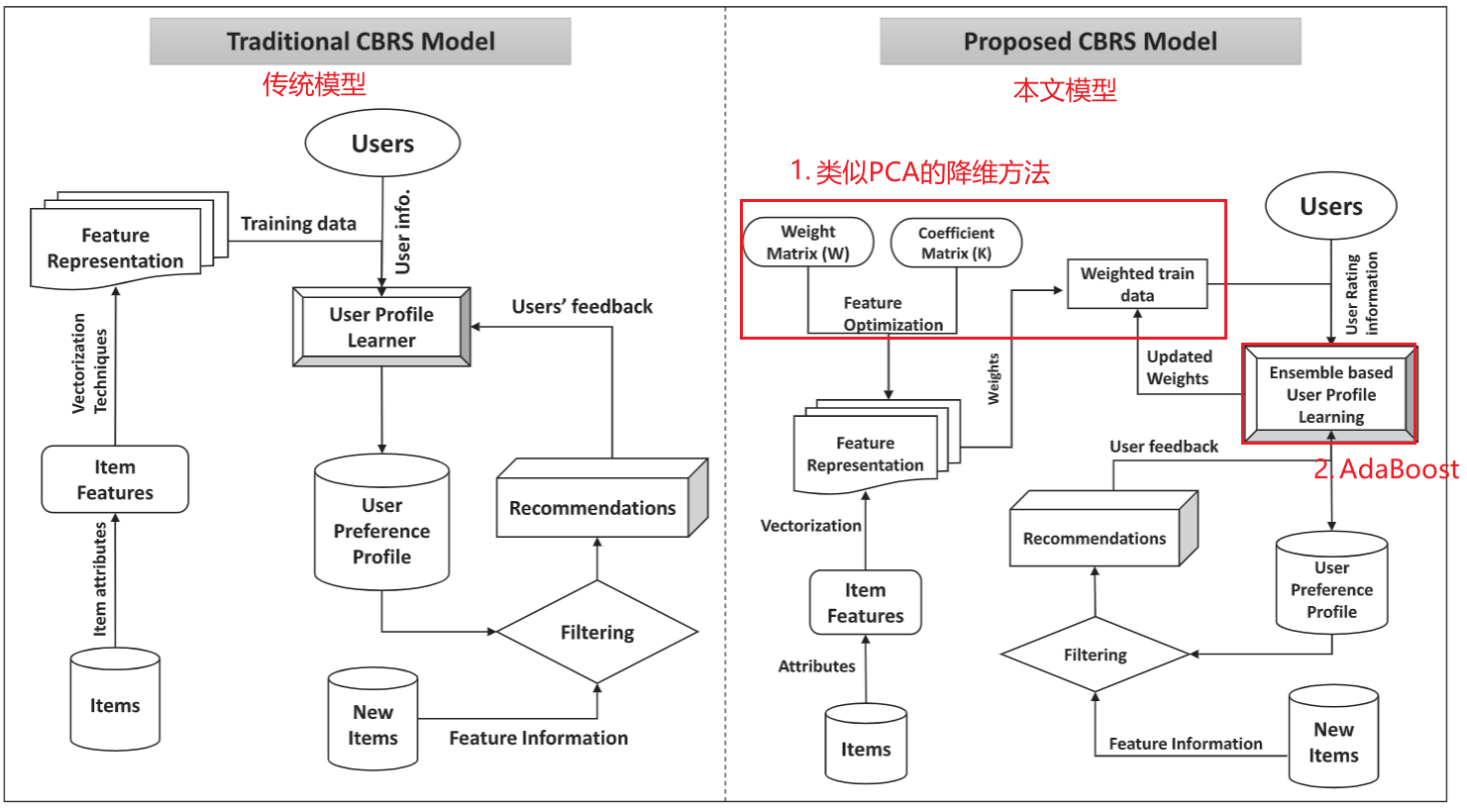
新物品用 New Items 表示,它先通过用户偏好画像(User Preference Profile)的过滤来判断是否要推送给用户,而用户偏好画像是由集成模型所表示的,过滤器会对 New Items 进行评级,选出一个评级,使得各个加权的分类器给出该评级的概率总和最大即可,把各个 News Items 以“非递增”(原文如此)的形式生成推荐。物品评级的数学形式如下,其中
2.2.4. 主要方法介绍
作者所谓两个创新中,其一,特征精炼可以看作是特征工程方法,该方法来自 Wang 等人的工作[1:1];而第二个点,采用 AdaBoost 并不算创新。这里主要梳理一下数据精炼方法。
这里目标式用的是 F 范数,用于衡量
论文中没有说 f 是多少,不严谨。原本特征数量是 d,如果 f < d 那就是做了降维;如果 f=d 那就只做了旋转。
K 的引入是 Wang 等人的工作[1:2]中的创新点,但是这篇论文中对 K 的解释就是:“将原始特征矩阵投影到所选特征矩阵的共享子空间”。
由于
这里
原论文第二行写错了,不是相减而是叉乘,这里改正
利用拉格朗日乘子法引入约束项:
求
求
给出更新公式:
综上所述,作者提出算法 1:精炼数据算法:

算法 2:AdaBoost 算法

2.2.5. 实验验证
- 使用了 ML-1M、Last.fm 和 Netflix 等基准推荐系统数据集进行测试。
- 实验结果显示,与现有基于内容的推荐系统模型相比,所提出的方法在推荐质量上有显著改进。
- 在 ML-1M、Last.fm 和 Netflix 数据集上,提出的 CBRS 模型在 Top-10和 Top-20推荐任务中的表现优于其他基线模型。
- 使用 NDCG 和 Precision@K 作为排名质量的评估指标,提出的模型在大多数情况下显著优于其他模型。
作者没有做消融实验验证他们的特征提取是否真正发挥了作用,也没有验证 AdaBoost 是否比其他模型优越。
2.2.6. 数据形式
本文使用了多个数据集,这里介绍其中一种电影评分数据集 MovieLens 的形式作为参考:
- 评分数据,包含字段:用户 ID,电影 ID,评分,时间戳
- 电影标签,包含字段:用户 ID,电影 ID,用户自定义标签(由单词或短语构成),时间戳
- 电影数据,包含字段:电影 ID,电影名称,题材(如动作,喜剧等等)
推荐系统的模型将评分作为标签,其他数据通过特征工程处理为学习数据,通过模型进行学习。
2.2.7. 讨论与结论
- 研究强调了在 CBRS 中获取有效物品特征信息的重要性,以及用户偏好模型的有效性。
- 提出的模型通过矩阵分解处理物品特征的稀疏性和不一致性,并通过 AdaBoost 集成学习来构建用户偏好模型,从而提高了推荐的质量。
- 未来的工作将研究基于深度学习的特征提取模型,以改进内容推荐系统中的特征细化过程。
2.3. 个人评价
创新点一般,两个点都是基于已有方法构建的,没有做充分的消融实验。但是该方案主要基于数学方法和统计学习,比较简单且稳定可靠,的确适合实际场景落地。
3. 参考文献
Wang, S., Pedrycz, W., Zhu, Q., & Zhu, W. (2015). Subspace learning for unsupervised feature selection via matrix factorization. Pattern Recognition, 48, 10–19. ↩︎ ↩︎ ↩︎